Caching 101
Caching, a multi-layered strategy that happens at every level of your infrastructure
November 19, 2025 · 5 min read
A beginner’s point of view
After spending countless hours optimizing my AI-powered applications and dealing with API rate limits, I’ve learned that caching is far more nuanced than most developers think. Sure, we all know it’s about “storing stuff to make things faster,” but the reality is much more complex and fascinating. I’m sharing everything today so you might avoid doing the same mistakes in the future. By the end of this article you’ll know it all about caching.
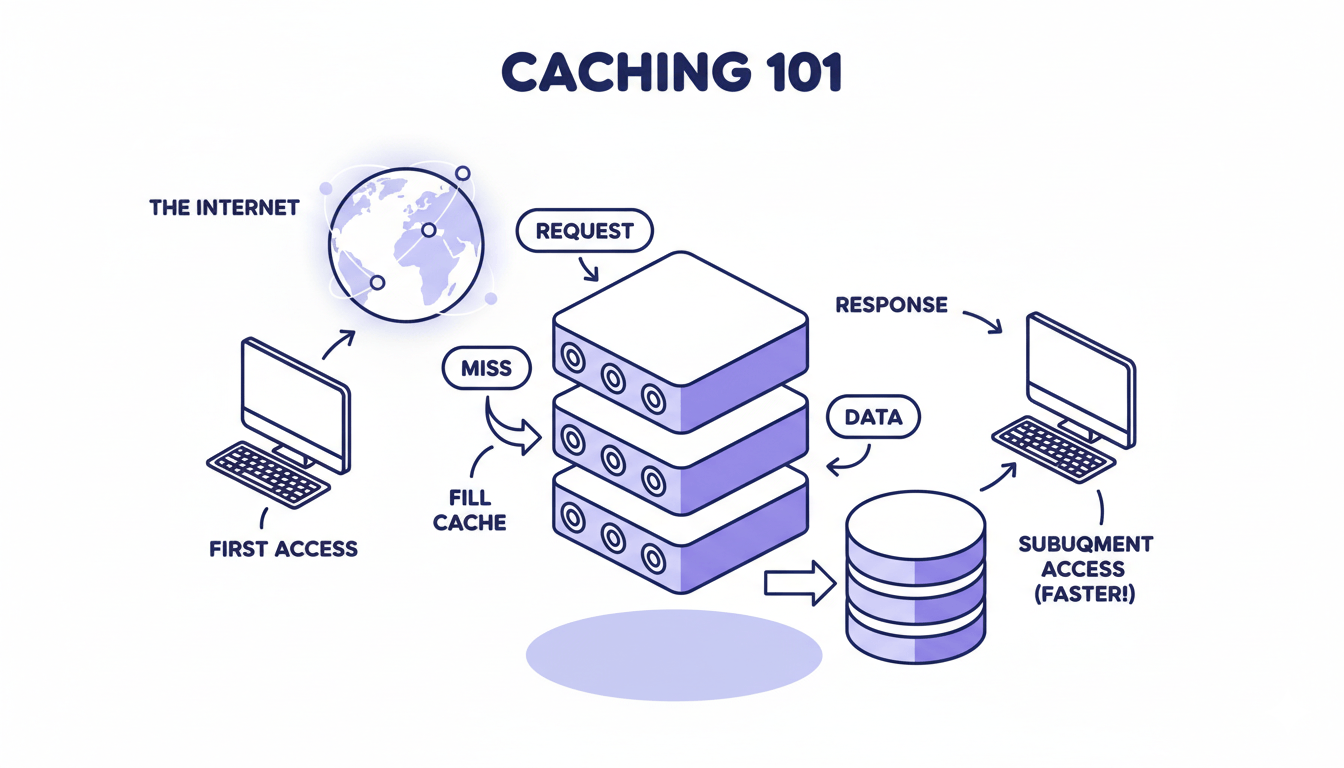
The Cache Misconception
When I started my development journey, I thought caching was simple. Save frequently used data somewhere fast, retrieve it when needed, done. But caching is actually a multi-layered strategy that happens at every level of your infrastructure, from CPU registers measured in nanoseconds to CDN edge servers thousands of miles away.
The first time I really understood this was when building my prospecting platform with conversational AI. I was making repeated calls to the ElevenLabs API for the same voice configurations, burning through my quota unnecessarily. That’s when caching transformed from a nice-to-have optimization to an absolute necessity.
Understanding the Cache Hierarchy
Think of caching like a series of increasingly distant storage locations. Your CPU has its own tiny, super fast cache that operates in nanoseconds. Then comes RAM, operating in microseconds. Further out, you have SSD storage in milliseconds, then network caches, and finally, the origin server that might take seconds to respond.
This hierarchy isn’t just academic knowledge. When I implemented Better Stack observability in my applications, I could actually see how requests traveled through these layers. A cache hit at the CDN level meant my origin server never even knew a request happened. That’s powerful stuff.
The Different Faces of Caching
Working with various projects has taught me that caching isn’t monolithic. Each type serves a specific purpose and understanding when to use which type is crucial.
Browser caching is your first line of defense. It’s completely free and requires zero infrastructure. By setting proper Cache-Control headers, you’re telling browsers to store your static assets locally. When I rebuilt my blog at bastienyoussfi.dev, implementing aggressive browser caching for my CSS and JavaScript files made subsequent page loads instantaneous. The browser doesn’t even make a network request.
Proxy caching sits between your users and your servers. This shared cache serves multiple users with the same content. I discovered its power when implementing a reverse proxy cache for my Auditex application. Instead of regenerating the same reports for different users, the proxy cache serves them instantly from memory.
CDN caching takes this concept global. After deploying my TikTok video generation engine, I realized that serving video assets from a single server was impossibly slow for users in different continents. CDNs solve this by caching content at edge locations worldwide. The first user in Tokyo might wait a second for content to propagate, but everyone after gets it in milliseconds.
Application caching is where things get really interesting. This includes object caches like Redis for database query results, page caches for entire HTML documents, and even opcode caches that store compiled code. When building my social media automation tool, Redis became essential for storing API tokens and rate limit counters.
The Art of Cache Invalidation
Phil Karlton famously said there are only two hard things in computer science: cache invalidation and naming things. After accidentally serving week-old data to a client because of aggressive caching, I can confirm the first part is absolutely true.
Cache invalidation is about knowing when your cached data is no longer valid and needs refreshing. The simplest approach is TTL or Time-To-Live, where content expires after a set duration. But this means you might serve stale content until expiry, or unnecessarily refetch fresh content.
Event-based invalidation is more sophisticated. When data changes, you actively purge related cache entries. In my webhook implementations for post-call analysis, I invalidate conversation caches whenever new analysis data arrives. This ensures real-time accuracy while maintaining performance.
Cache busting through versioning is my favorite technique for static assets. Instead of worrying about invalidation, you change the filename. Your style.css becomes style.v2.css, forcing browsers and CDNs to fetch the new version. It’s simple, reliable, and requires no complex purging logic.
HTTP Headers: The Unsung Heroes
Understanding HTTP cache headers transformed how I build web applications. These headers are your contract with browsers and caching servers, telling them exactly how to handle your content.
Cache-Control: public, max-age=31536000 tells everyone to cache this resource for a year. Perfect for versioned static assets. Cache-Control: private, max-age=3600 means only the user’s browser should cache it, not shared proxies. Essential for personalized content. Cache-Control: no-store means never cache this, period. Critical for sensitive data.
The ETag header provides versioning without timestamps. When content changes, its ETag changes, allowing browsers to validate if their cached version is still current. The Vary header is particularly clever, creating different cache entries based on request headers. Vary: Accept-Encoding ensures gzipped and non-gzipped versions are cached separately.
Caching Strategies That Actually Work
Through trial and error, I’ve learned that different scenarios require different caching strategies.
Cache-Aside, also known as lazy loading, is my go-to for most applications. You check the cache first, and on a miss, you fetch from the source and update the cache. It’s simple, predictable, and works great for read-heavy workloads like my blog content.
Write-Through caching updates both cache and database synchronously. While it ensures consistency, the added latency makes it unsuitable for my real-time AI applications where every millisecond counts.
Write-Behind caching is fascinating but risky. You update the cache immediately and asynchronously update the database later. The performance is incredible, but the possibility of data loss keeps me awake at night. I only use this for non-critical data like analytics metrics.
Refresh-Ahead is sophisticated, proactively refreshing cache entries before they expire. When I implemented this for frequently accessed configuration data in my ElevenLabs voice agents, it eliminated cache misses entirely during peak hours.
Real-World Implementation
Let me share a practical Nginx configuration that has served me well across multiple projects. This setup implements proxy caching with smart invalidation strategies.
proxy_cache_path /var/cache/nginx levels=1:2
keys_zone=api_cache:10m max_size=1g
inactive=60m use_temp_path=off;
server {
location /api/ {
proxy_cache api_cache;
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
proxy_cache_valid any 1m;
proxy_cache_use_stale error timeout updating
http_500 http_502 http_503 http_504;
proxy_cache_background_update on;
proxy_cache_lock on;
add_header X-Cache-Status $upstream_cache_status;
proxy_pass http://backend;
}
}The proxy_cache_use_stale directive is crucial here. It serves stale content when the origin is down, ensuring availability even during outages. The proxy_cache_lock prevents cache stampedes when popular content expires.
For Redis object caching in my Node.js applications, I use a pattern that handles both cache hits and misses gracefully.
async function getCachedData(key, fetchFunction, ttl = 3600) {
const cached = await redis.get(key);
if (cached) {
return JSON.parse(cached);
}
const fresh = await fetchFunction();
await redis.setex(key, ttl, JSON.stringify(fresh));
return fresh;
}This abstraction means I can add caching to any data fetch with minimal code changes. It’s been invaluable for reducing database load in my SaaS applications.
CDN vs Traditional Caching: The Reality Check
When I first discovered CDNs, I thought they were just geographically distributed caches. While that’s technically true, the practical differences are substantial.
CDNs excel at static content delivery and geographic distribution. They’re managed services where you pay per gigabyte transferred. Setup involves changing DNS settings and configuring cache rules through a dashboard or API. They offer automatic scaling and often include DDoS protection.
Traditional caching servers give you complete control but require infrastructure management. You decide exactly what to cache, for how long, and how to invalidate it. They handle both static and dynamic content effectively and can implement complex caching logic specific to your application.
For my projects, I use both. CloudFlare serves static assets and provides DDoS protection, while Nginx and Redis handle application-specific caching on my Hetzner VPS.
Metrics That Matter
Monitoring cache performance has taught me what metrics actually matter. Cache hit ratio is the north star metric, calculated as hits divided by total requests. For static content, aim for above 80 percent. Below that suggests TTLs are too short or content is too diverse.
Byte hit ratio shows bandwidth savings, crucial when serving large files like my AI-generated videos. Response time comparisons between cached and non-cached requests reveal actual user impact. Origin offload percentage shows how much load you’re removing from your servers.
I track these metrics religiously using Grafana dashboards connected to my Better Stack monitoring. Seeing a 95 percent cache hit ratio is incredibly satisfying and translates directly to reduced infrastructure costs.
Security: The Often Forgotten Aspect
Caching security vulnerabilities can be subtle but devastating. Never cache sensitive information like authentication tokens or personal data. Always use the private directive for user-specific content.
Cache poisoning attacks involve tricking your cache into storing malicious content. Proper cache key normalization and request validation prevent this. I learned this after someone tried to poison my CDN cache with XSS payloads.
Always validate that your caching layers respect security headers. CORS headers, in particular, must be properly cached to avoid access control bypasses.
The Conclusion
Caching is a fundamental optimization that goes far beyond simple key-value storage. It’s a multi-layered strategy that requires understanding your content, your users, and your infrastructure.
Start with the low-hanging fruit like browser caching and CDN integration for static assets. Add application-level caching for expensive operations. Implement proper cache invalidation strategies from day one because retrofitting them is painful.
Most importantly, measure everything. Cache effectiveness is quantifiable, and the metrics will guide your optimization efforts. Every millisecond saved translates to better user experience and reduced infrastructure costs.
Working with caching has taught me that performance optimization isn’t just about writing efficient code. It’s about architecting systems that leverage every layer of the stack. Whether you’re building a simple blog or a complex AI platform, understanding caching will make you a better developer and your applications faster and more scalable.
Remember, caching isn’t just about making things faster. It’s about building resilient systems that gracefully handle load spikes, network failures, and global distribution. Master caching, and you’ll master scalability.